Regarder une publicité pour télécharger gratuitement
Avis Softonic
Pont MCP local qui exécute des modèles hébergés par Ollama localement
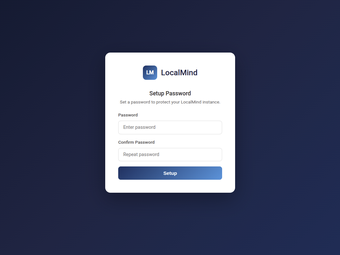
localmind, développé par Fedcal, est un serveur de protocole de contexte de modèle open-source qui connecte les LLM locaux aux clients AI de bureau. L'application expose la génération de texte et la gestion des modèles via une instance locale d'Ollama, permettant aux clients MCP tels que Claude Desktop d'appeler des modèles hébergés localement pour des réponses aux invites. Elle prend en charge la liste, le tirage et la suppression des modèles Ollama, la messagerie MCP standard et l'inférence locale pour réduire l'utilisation des API externes. Conçu pour les développeurs, les chercheurs et les utilisateurs soucieux de leur vie privée qui ont besoin d'un accès aux modèles locaux dans les flux de travail AI de bureau.
Pour quelles tâches pouvez-vous réellement l'utiliser ?
localmind agit comme un pont entre les modèles locaux et les clients compatibles MCP, rendant les LLM hébergés localement appelables depuis des outils de bureau. Les tâches pratiques incluent la génération de texte sur l'appareil, l'utilisation de modèles comme outils d'assistance à l'intérieur de clients comme Claude Desktop, et la maintenance de bibliothèque de modèles de base. Les opérations typiques exposées par le serveur sont :
interroger les modèles pour des réponses générées
lister les modèles locaux disponibles
tirer ou supprimer des modèles de la bibliothèque Ollama
Ces résultats s'intègrent dans des flux de travail qui nécessitent des sorties textuelles exécutées localement.
Quelle est la fiabilité des sorties par rapport aux modèles cloud ?
La qualité de sortie dépend du modèle Ollama choisi et du matériel de l'utilisateur. localmind lui-même achemine les invites vers des modèles pris en charge par Ollama, tels que Llama 3, Mistral et Phi-3, donc les réponses générées reflètent les forces et les faiblesses de chaque modèle. La performance et la fidélité varient selon le choix du modèle et la capacité de calcul local ; la vitesse d'inférence et la qualité de réponse suivent donc le modèle sous-jacent et la machine exécutant Ollama plutôt que le code du serveur.
Quelles entrées et configurations sont nécessaires pour fonctionner ?
Le serveur nécessite une instance Ollama en cours d'exécution et un client MCP pour fonctionner. Vous devez exécuter Ollama localement et utiliser un client compatible MCP, par exemple Claude Desktop, pour que le serveur puisse transférer les demandes. localmind est implémenté pour des environnements qui prennent en charge Node.js et Ollama, y compris Windows, macOS et Linux. Les fonctionnalités de gestion des modèles permettent aux utilisateurs de tirer de nouveaux modèles de la bibliothèque Ollama et de supprimer ceux qui ne sont pas utilisés, mais le serveur ne peut pas fonctionner sans le service Ollama local.
Est-ce adapté aux flux de travail axés sur la confidentialité ou aux développeurs ?
L'exécution locale est l'objectif principal de conception, ce qui réduit la dépendance aux API externes en maintenant l'inférence sur le matériel de l'utilisateur. Le projet est open-source et positionné dans l'écosystème MCP, et les retours de la communauté sur GitHub soulignent son implémentation simple. Ce design convient aux développeurs et aux chercheurs qui gèrent des modèles locaux et souhaitent une intégration de bureau ; les utilisateurs s'attendant à des services cloud entièrement gérés devront faire un travail opérationnel supplémentaire pour maintenir les modèles et le matériel.
Choix pratique pour les utilisateurs pratiques qui peuvent exécuter des modèles locaux
localmind est une option pragmatique pour les développeurs et les chercheurs soucieux de la vie privée qui exécutent déjà Ollama et souhaitent une intégration du client MCP. Cela nécessite une gestion des modèles locaux et un matériel suffisant pour l'inférence, donc les utilisateurs sans ces ressources ou qui préfèrent des services cloud gérés le trouvent moins adapté. Pour ceux qui sont à l'aise avec les outils locaux, cela offre une voie prévisible pour garder les invites et les données sur l'appareil tout en utilisant des clients IA de bureau familiers.
Les plus
L'intégration directe d'Ollama expose une large gamme de modèles open-source
Le protocole MCP standardisé garantit la compatibilité avec les clients MCP
Exécute l'inférence sur du matériel local, réduisant la dépendance aux API externes
Les moins
Nécessite Ollama installé et en cours d'exécution sur la même machine
La performance et la qualité de sortie dépendent du matériel local et du modèle choisi
Nécessite un client compatible MCP tel que Claude Desktop pour être utile
Les lois sur l’utilisation des logiciels varient d’un pays à l’autre. Nous n’encourageons ni ne tolérons l’utilisation de ce programme non conforme à la loi. Softonic peut recevoir une compensation si vous cliquez ou achetez un des produits présentés ici.